2nd Summit Day 4
Friday 11-Nov-2011. Mozilla SF.
Video:
- AM-part1 (350MB Quicktime, 20min, quiet)
- AM-part2 10:50-12:50 (300MB QT, 2 hours, quiet)
- PM (1GB QT, 5 hours)
Attendees (with IRC nicks)
- Brian Warner (warner)
- Drew Perttula (drewp)
- Zooko (zooko)
- David-Sarah Hopwood (davidsarah)
- Zancas (zancas)
- Zack Weinberg (zwol)
- Kevan Carstensen (kevan)
- Peter Secor (secorp)
- Frederik Braun (ChosenOne)
- Nathan Wilcox (nejucomo)
- Leif
- Jonathan Moore
Web Control-Panel
- explained goals to drewp, he found the full-page iframe weird (removing an insecure-looking URL from the address bar to hide the fact that we're using an insecure-looking URL for the iframe?)
leasedb crawler
- leasedb: SQLite database which holds information about each share, all leases, all Accounts. Used for fast computation of quotas, thresholds, enforcement of server policy. Might be modified externally (give ourselves room to use an external expiration/policy process).
- goals: discover manually added/new shares (including bootstrap and after deletion of corrupt DB), discover manually deleted shares, tolerate backends which only offer async operations (deletion, share-is-present queries)
- approach: have a slow Crawler which notices new/old shares, updates DB. New (manually-added) shares get a "starter lease" to keep share alive until normal Account leases are established.
- expiration: done periodically, remove all leases that have expired, then check their shares to see if numleases==0, then remove shares
- concerns: race conditions between manually-added shares and expired leases, or manually-deleted shares and added leases
- solution: "garbage" flag on the share-table entry
- four state bits per Share entry: S=share-is-present, ST=share-table-has-entry, L=leases-present, G=share-table-is-garbage
- event-triggered, either by a crawler tick, or by the backend responding to a deletion request, or by the backend responding to a is-the-share-there query
- if S but !ST !L !G, new share: add ST, add starter lease to L
- if S and ST but !L !G, set G and send a deletion request
- if ST and G but !S, that means we just deleted it, so clear ST and G
- if an upload request arrives while G is set, defer: cannot accept upload until share is really gone, will be able to accept again in the future
Kevan: #1382 share-placement algorithm
- current algorithm doesn't always find a placement that meets H criteria
- there are situations (covered in unit tests) where a valid placement exists, but the algorithm cannot find it
- first refactoring step: consolidate share-placement into a single object
- you send in data about the state of the world, it does some computation, then tells you what you need to do, including asking for more servers
- Kevan has a better placement algorithm built, his master's thesis (almost done) proves it is sound and complete
- new algorithm effectively starts with a full graph, trims edges until only the necessary ones are left
- brian is concerned about performance, doesn't want this to limit our
ability to scale to thousands of servers. His performance desiderata:
200 shares, 1000 servers, algorithm should complete within a second
- davidsarah says no problem
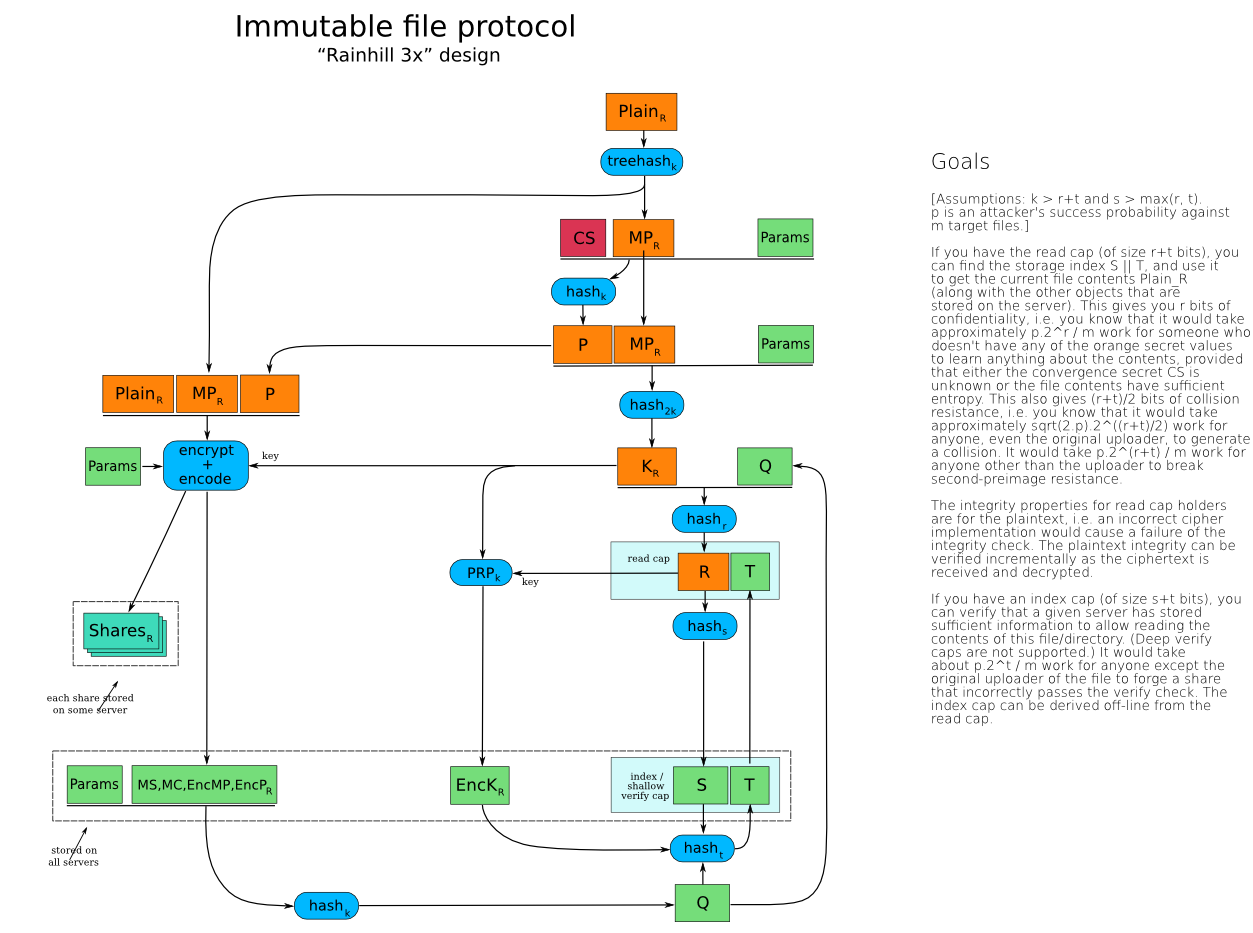
David-Sarah: Rainhill
- first explained current CHK
- Brian explained current dirnodes, transitive-readonly, super-encryption of writecap column, utility of deep-verify-caps
- David-Sarah then explained "Railhill-3x", an incremental step
(immutable-only) which has readcap and verifycap, and went through the
security requirements in each piece
- the length of various intermediate fields directly affects the ability to perform various attacks
- finding a collision on the readcap would enable variations of Christian Grothoff's "Two-Face" attack (the one fixed in v1.2.0)
- finding a pre-image on the readcap would allow an attacker to create new files that matched an existing readcap
- finding a pre-image on the verifycap (to the extent that can be checked by the server) would enable "roadblock" attacks, where attackers could fill SI slots with junk data and prevent the upload of real shares
- then expanded to the full Rainhill-3 (although still just immutable, not mutable)
- lots of discussion. We've been over a lot of these issues before, two
or three years ago, so a lot of it was paging tertiary memories back
into our brains. Some concerns:
- upload flow vs convergence: in most short-cap approaches, the full SI
isn't known until the end of the upload. That makes it hard to
discover pre-existing shares. A smaller number of bits (hash of P, if
I remember the diagram correctly) can be stored in the share and
queried at the start of upload
- server would need to retain table mapping P to full SI
- everyone acknowledged tradeoff/exclusivity between convergence and streaming (one-pass) upload. Goal is to enable uploader to choose which they want.
- integrity checks on the decrypted write-column (or read-column, in the presence of deep-verify). In simpler designs, having a plaintext hash tree (with the merkle root encrypted by the readcap, to prevent Drew Perttula's partial-guessing attack) also lets us detect failures in the encryption code (i.e. a fencepost error in AES CTR mode causing corrupted decryption). It'd be nice to have similar protection against decryption failures of each separate column. We concluded that the current Rainhill design doesn't have that, and readers would need to compare the e.g. writecap-column contents against the readcap-column as a verification step.
- upload flow vs convergence: in most short-cap approaches, the full SI
isn't known until the end of the upload. That makes it hard to
discover pre-existing shares. A smaller number of bits (hash of P, if
I remember the diagram correctly) can be stored in the share and
queried at the start of upload
add-only caps
- lots of discussion about how "add-record" cap would work
- lattice of caps: petrify->write, write->add, add->verify, write->read, read->deepverify, deepverify->verify
- preventing rollback
- overall goal is to enable a single honest server, or a single client-retained value, to prevent rollback
- also to prevent selective-forgetfulness: adding record A, then adding record B, server should not be able to pretend they've only heard of record B
- general idea was a form of Lamport vector clocks, but with hash of current set of known records instead of counters. Client might get current state hash from server 1, send update to server 2 which includes that hash (and gets S2's hash), etc around the ring through serverN, then one last addition to server 1 (including SN's hash). To rollback, attacker would need to compromise or block access to lots of servers. (brian's mental image is a cylindrical braid/knit: servers lie on the circle, time/causal-message-ordering extends perpendicular to the circle, each S[n].add(S[n-1].gethash()) message adds another stitch, which would have to be unwound to unlink an addition). OTOH we want to avoid making it necessary to talk to all servers to retrieve/verify the additions
- general sense was that Bitcoin's block chain is somehow related. Maybe servers could sign additions.
general project direction
- various use cases, competitors, developer interests
- Tahoe is slower than many new/popular distributed storage systems:
Riak / Cassandra / Mongo / S3(?) / etc.
- many things didn't exist when we started.. now that other folks have developed technology, we could take advantage of it
- core-competencies/advantages of tahoe:
- provider-independent security
- ease of self-reliant setup (running a personal storage server), vs establishing an S3 account or building a Hbase server
- fine-grained sharing
- disadvantages (relative to some competitors, not all):
- slower
- not really POSIX, requires application-level changes
- mutable-file consistency management
- perceived complexity (either by users or by developers)
- potentially-interesting hybrids:
- use S3 for reliability, k=N=1, but encryption/integrity frontend (this is what LAE offers, but it could be more built-in)
- use Dropbox for reliability and distribution, but with encryption/integrity frontend
- different developers have different because-its-cool interests
- brian: Invitation-based grid setup, easy commercial backends, universally-retrievable filecaps with/without a browser plugin, Caja-based confined browser-resident web-app execution, confined remote code execution services, bitcoin-based social accounting, eventually work back up to most of the original mojonation vision
- zooko?: LAE
- davidsarah?: mentioned Rainhill, mutable-file consistency
- jmoore?: add-only caps for logging
Last modified at 2011-11-12T22:35:34Z
Last modified on 2011-11-12T22:35:34Z
Attachments (4)
-
day4-leasecrawler.jpg
(1.0 MB) -
added by warner at 2011-11-12T20:09:39Z.
whiteboard: leasedb crawler design
-
day4-directions.jpg
(1.0 MB) -
added by warner at 2011-11-12T20:10:05Z.
whiteboard: newcap desired features, project directions
-
immutable-rainhill-3x.png
(180.2 KB) -
added by warner at 2011-11-12T20:44:12Z.
Rainhill-3x (immutable)
-
immutable-rainhill-3.png
(232.7 KB) -
added by warner at 2011-11-12T20:44:36Z.
Rainhill-3 (immutable)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}