Opened at 2010-11-23T23:36:04Z
Closed at 2011-08-01T15:16:38Z
#1268 closed defect (fixed)
downloader/share: coalesce mutiple Share.loop() calls
| Reported by: | warner | Owned by: | warner |
|---|---|---|---|
| Priority: | major | Milestone: | 1.9.0 |
| Component: | code-encoding | Version: | 1.8.0 |
| Keywords: | download performance reviewed | Cc: | |
| Launchpad Bug: |
Description
As alluded to in comment:92:ticket:1170 , the behavior of src/allmydata/immutable/downloader/share.py (in the Share class) should be improved. Each time a data-fetch response arrives from the server (either for a data block or for a couple of hash nodes), a call to Share.loop is queued. When run, loop recomputes the desire/satisfaction bitmap (a Spans instance), which takes a nontrivial amount of time. (although much less than it used to, before some of the issues in #1170 were fixed).
The problem is that we're recomputing it far too many times, and most of them are redundant. For example, supposed we get responses to 4 requests in a big bunch (because they all arrived in the same network packet). Foolscap will queue an eventual-send for the response Deferreds all on the same reactor turn. When those fire, they'll update the what-data-we've-received DataSpans and then queue a call to loop(). All four messages will be processed before the first call to loop() occurs.
The first loop() pass will process the received spans, deliver the completed block to the caller that asked for it, and then update the desire/satisfaction bitmaps in preparation for whatever the next block might be. The second loop() pass will recompute the bitmaps, even though no changes have occurred (no new blocks were requested, no new responses received). The third and fourth loop() passes will do the same.
attachment:viz-3.png:ticket:1170 shows a bit of it: the pale yellow candlestick-like shapes (just below the "misc" label) are the calls to measure satisfaction and recompute the desire bitmap. The first call spends a lot of time in satisfy() (to deliver the completed block), and then a moderare amount of time in desire() (to figure out what we need next). The second and third calls both spend a tiny amount of time in satisfy() (since there are no completed blocks ready to be delivered), but then spend the same moderate amount of time in desire() recomputing the same bitmap as before.
{kind=link}
{kind=link}
This gets worse when there are a lot of loop() calls queued, which means it gets worse when there are lots of (small) hash node requests coming back. As a result, the amount of wasted time is larger just after segments which trigger most hash-node requests. This distribution is an interesting function (probably one of those exciting sequences in the OEIS), but basically it's zero for all odd-numbered segments, and gets larger as you switch over higher branches in a binary tree (so the max is for seg0, the next highest is for NUMSEGS/2, third highest is for NUMSEGS/4 and 3*NUMSEGS/4, etc).
attachment:180c2-viz-delays.png:ticket:1170 shows this variation: the time between the end of the last pink block() request for any given segment, and the end of the segment() request, is mostly filled with this wasted recomputation. The time spent there is larger for some segments than others. In the example chart, the largest set of block requests (for the NUMSEGS/2 midpoint segment) has about 70ms of wasted time, whereas the very next segment (NUMSEGS/2+1, which needs no extra hash nodes) only spends about 10ms in that phase.
{kind=link}
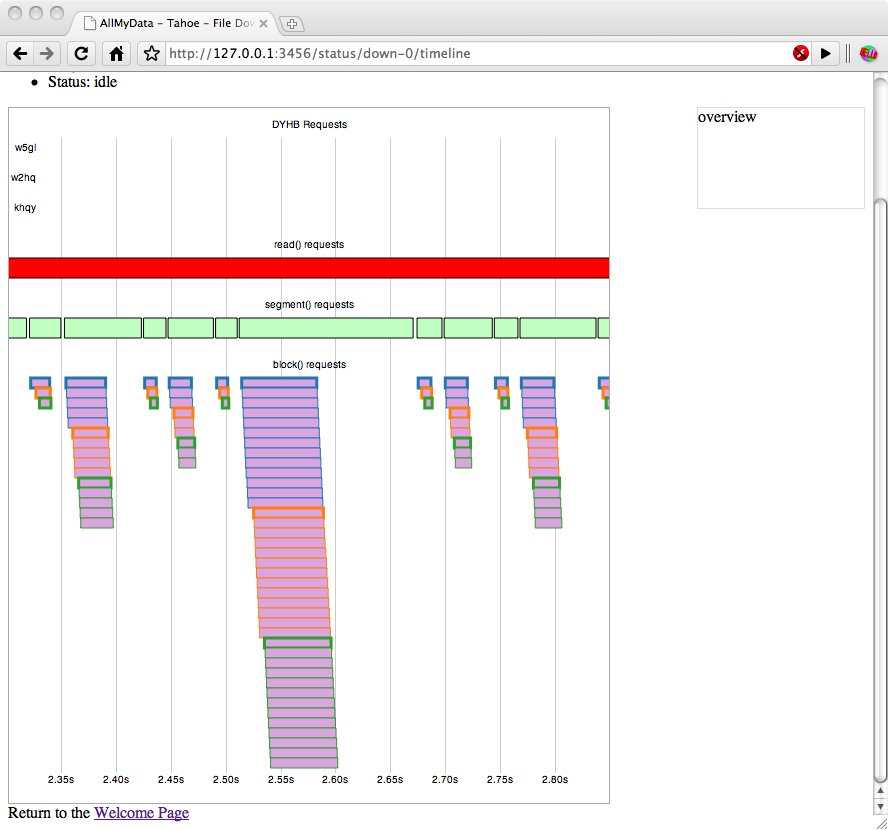{kind=link}
The total amount of time wasted scales (linearly, I think) with NUMSEGS. It should also scale linearly with 'k', since there's a separate Share instance (and thus a whole set of these queued loop() calls) for each active share.
This problem is hypothesized to be involved with #1264 (slow downloads for large k), although the rough measurements I did for #1170 suggest that the time spent is too small (8% for a local one-CPU download of a 12MB file) to explain #1264.
The fix will be to have Share refrain from queueing redundant calls to loop():
- factor out all the places that do eventually(self.loop) into a single schedule_loop() function
- change schedule_loop() to check a flag:
- if unset, set the flag and call eventually(self.loop)
- if set, do nothing
- clear the flag at the start of loop()
Then we should re-run the #1264 tests to see if there's a significant change.
Attachments (1)
Change History (7)
comment:1 Changed at 2010-11-24T07:43:19Z by zooko
comment:2 Changed at 2011-05-21T16:21:00Z by davidsarah
- Keywords download performance added
comment:3 Changed at 2011-08-01T04:42:53Z by warner
- Keywords review-needed added
- Milestone changed from undecided to 1.9.0
The patch is pretty simple. Manual checking on a 12MB file shows a reduction in the number of calls to loop() from around 1200 to about 580, and a casual check shows the download time drops from 4.2s to 4.0s, so it looks like it's doing its job.
comment:4 Changed at 2011-08-01T04:46:42Z by davidsarah
- Keywords reviewed added; review-needed removed
Looks good.
comment:5 Changed at 2011-08-01T04:47:43Z by davidsarah
- Owner set to warner
comment:6 Changed at 2011-08-01T15:16:38Z by Brian Warner <warner@…>
- Resolution set to fixed
- Status changed from new to closed
In c9def7697757bdae:
I wrote up some notes about François's profiling results over on comment:9:ticket:1264. It might shed light on this ticket.