The atlasperf1 grid
All these performance tests are run on a four-machine grid, using hardware generously provided by Atlas Networks. Each machine is a dual-core 3GHz P4, connected with gigabit(?) ethernet links. Three machines are servers, running two servers each (six storage servers in all), each on a separate disk. The fourth machine is a client. The storage servers are running a variety of versions.
Versions
These tests were conducted from 19-Sep-2011 to 22-Sep-2011, against Tahoe versions 1.7.1, 1.8.2, and trunk (circa 19-Sep-2011, about 8e69b94588c1c0e7).
Overall Speed
With the default encoding (k=3), trunk MDMF downloads on this grid run at 4.0MBps. Trunk CHK downloads run at 2.6MBps. (For historical comparison, the old CHK downloader from 1.7.1 runs at 4.4MBps). CHK performance drops significantly with larger k.
MDMF (trunk)
MDMF is fast! Trunk downloads 1MB/10MB/100MB MDMF files at around 4MBps. Download speed drops linearly with k, k=60 takes roughly 2x more time than k=30. Partial reads take the expected amount of time: O(data_read), slightly quantized near the 128KiB segment size.
- MDMF partial reads, 100MB attachment:MDMF-100MB-partial.png (timing6.out)
- MDMF partial reads, 1MB attachment:MDMF-1MB-partial.png (timing6.out)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CHK (trunk)
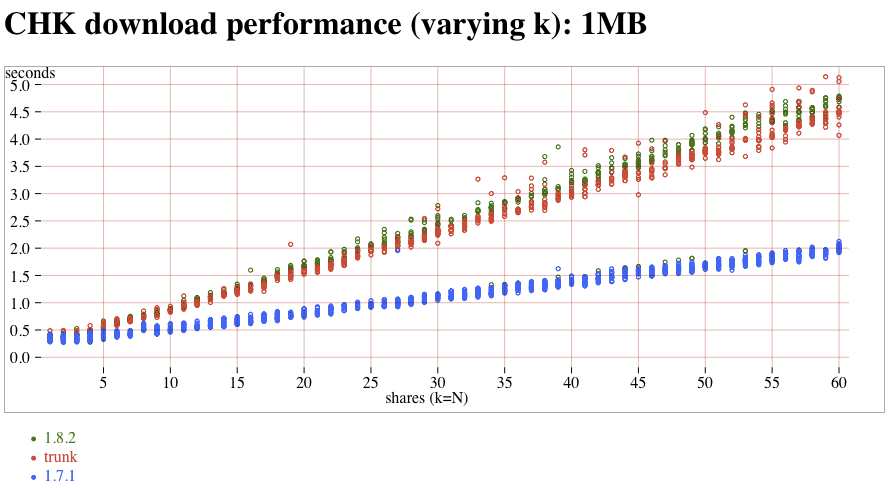
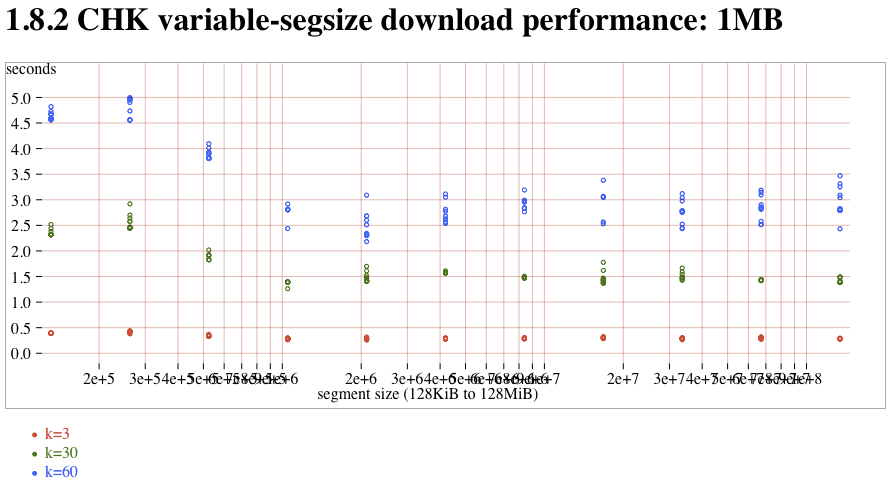
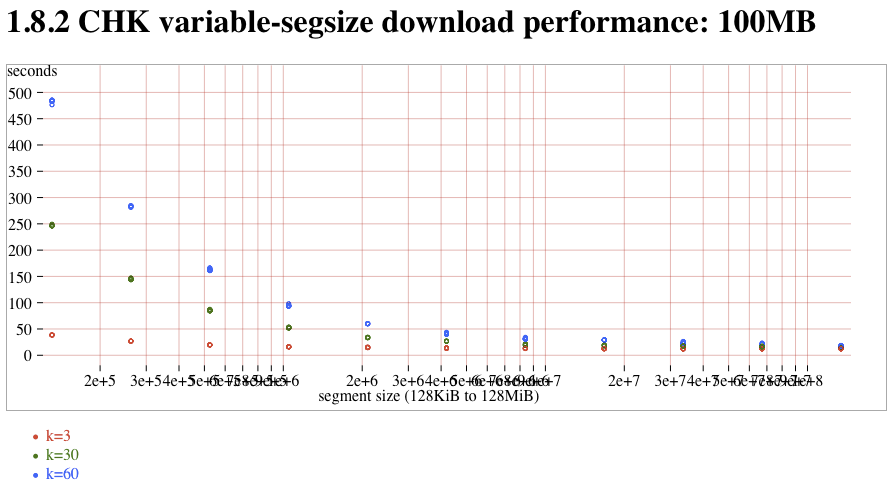
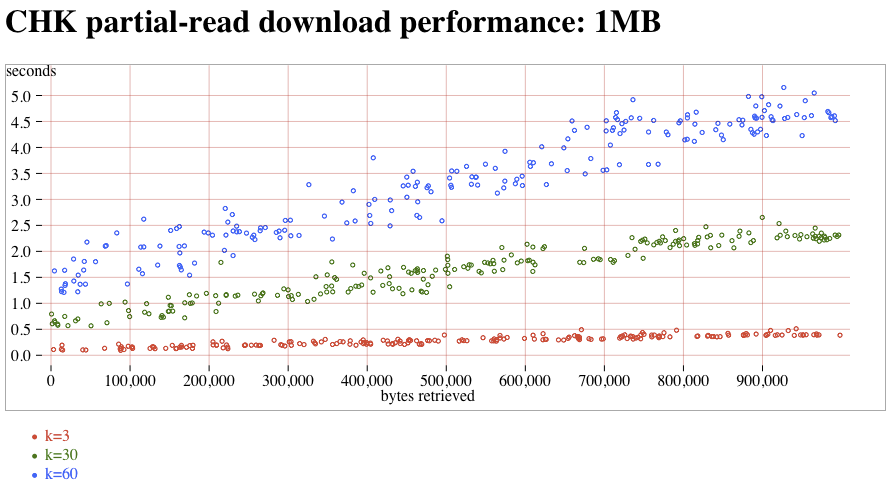
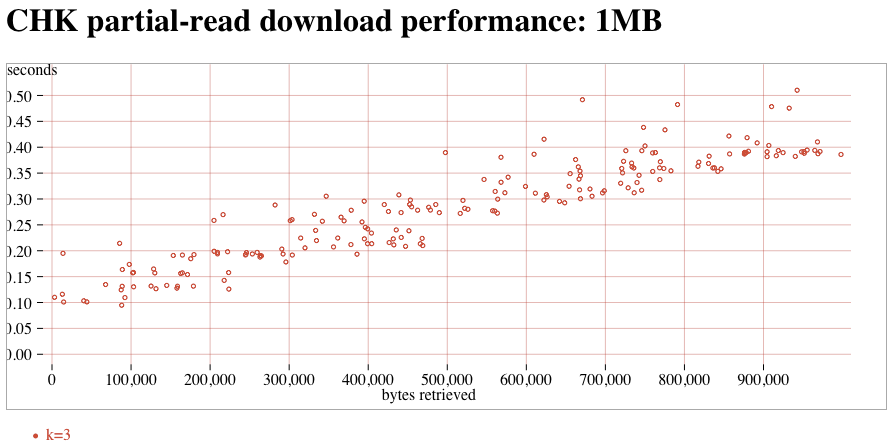
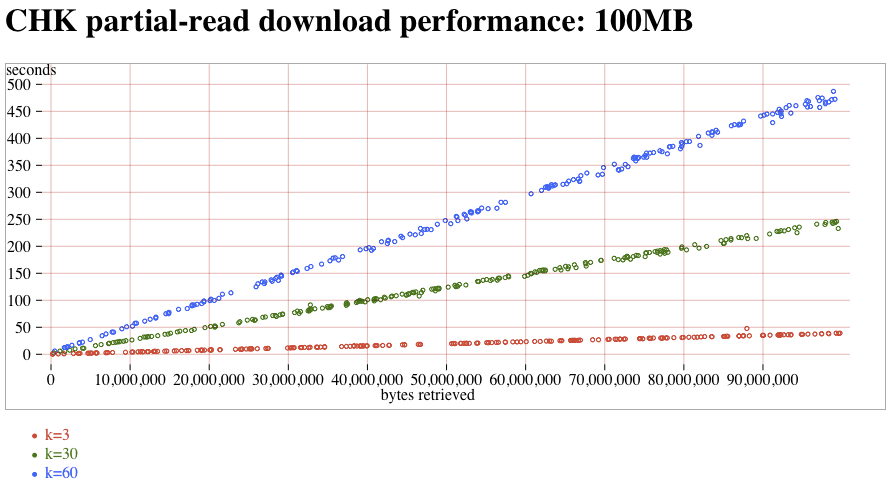
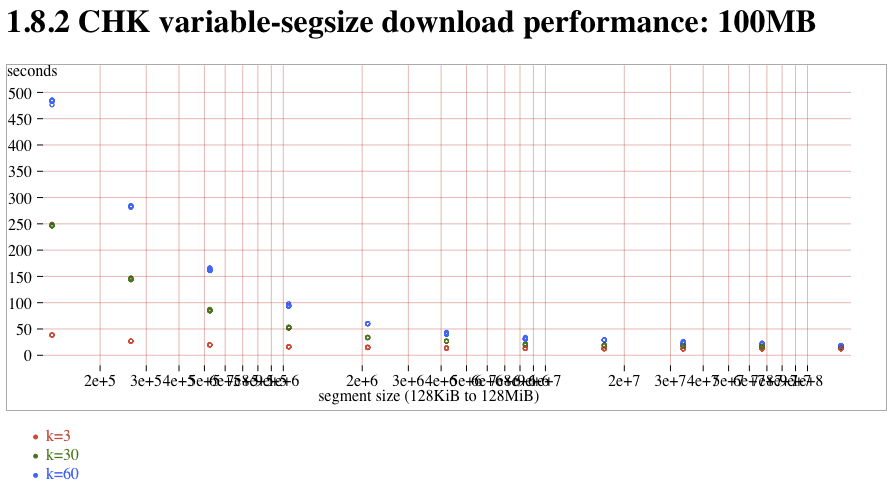
The new-downloader (introduced in 1.8.0) does not saturate these fast connections. Compared to the old-downloader (in 1.7.1), downloads tend to be about 3x slower. (note that this delay is probably completely hidden on slow WAN links, and it's only the fast LAN connections of the atlasperf1 grid that exposes the delay). In addition, both old and new downloaders suffer from a linear slowdown as k increases. On the new-downloader, k=60 takes roughly 2x more time than k=30. Trunk contains a fix for #1268 that might improve speeds by 5% compared to 1.8.2. Partial reads take the expected amount of time, although the segsize-quantization was nowhere nearly as clear as with MDMF.
- CHK (1.7.1/1.8.2/trunk) read versus k, 1MB attachment:CHK-1MB-vs-k.png (t4/t/t3)
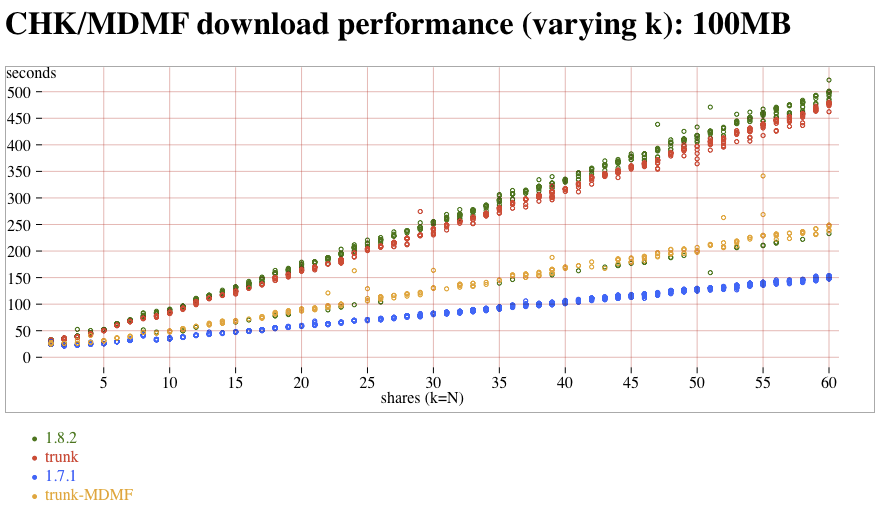
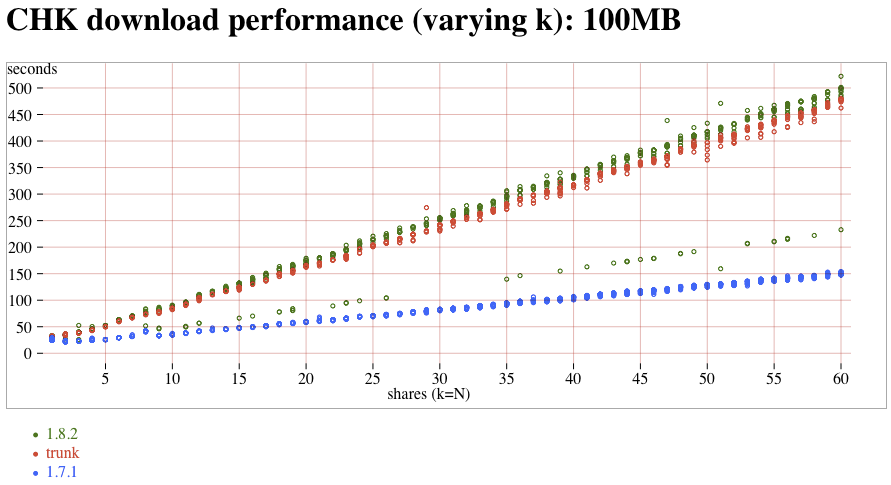
- CHK (1.7.1/1.8.2/trunk) and MDMF (trunk) read versus k, 100MB attachment:CHKMDMF-100MB-vs-k.png (t4/t/t3/t8)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- CHK (1.8.2) read versus segsize, 1MB attachment:CHK-1MB-vs-segsize.png (t2)
- CHK (1.8.2) read versus segsize, 100MB attachment:CHK-100MB-vs-segsize.png (t2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- CHK (trunk) partial reads, 1MB attachment:CHK-1MB-partial.png (t7)
- CHK (trunk) partial reads, k=3, 1MB attachment:CHK-1MB-k3-partial.png (t7)
- CHK (trunk) partial reads, 100MB attachment:CHK-100MB-partial.png (t7)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Likely problems include:
- high k and default segsize=128KiB means tiny segments, like 2KB when k=60.
- lots of reads, lots of foolscap messages, and marshalling is probably slow
- disk seeks to gather hash nodes from all over the share
Likely fixes include:
- add a readv() API, to reduce the number of Foolscap messages in flight
- prefetch hash-tree nodes, by reading larger chunks of the tree at once.
old-downloader cheated by reading the whole hash tree at once, violating
the memory footprint goals (requires O(numsegments) memory), but probably
tolerable unless the filesize is really large.
- note that 1.7.1 "cheats" with both the crypttext_hash_tree and the block_hash_tree. MDMF in trunk cheats with the block_hash_tree and does not have a crypttext_hash_tree
- encourage use of larger segsize for large files (at the expense of alacrity)
- use unencrypted HTTP for share reads
readv() is the least-work/most-promising, since MDMF has readv() and is faster than trunk, although not as fast as 1.7.1.
Future Tests
- measure alacrity: ask for random single byte, measure elapsed time
- measure SDMF/MDMF modification times
- measure upload times
- using existing data as a baseline, detect outliers in real-time during the benchmark run, and capture more information about them (their "Recent Uploads And Downloads" event timeline, for starters)
Additional Notes
Some graphs were added to http://tahoe-lafs.org/trac/tahoe-lafs/ticket/1264#comment:17 .
Complete benchmark toolchain and data included in attachment:atlasperf.git.tar.gz
Zooko raised the question (20-May-2012) on IRC:
<zooko> warner: this page says that K=60 takes twice as long as K=30: <zooko> https://tahoe-lafs.org/trac/tahoe-lafs/wiki/Performance/Sep2011 <zooko> But these graphs seems to show those two taking about the same time as each other: <zooko> https://tahoe-lafs.org/trac/tahoe-lafs/attachment/wiki/Performance/Sep2011/MDMF-100MB-partial.png <zooko> https://tahoe-lafs.org/trac/tahoe-lafs/attachment/wiki/Performance/Sep2011/MDMF-1MB-partial.png <zooko> I hope the latter is true. :-)
Those partial-read graphs certainly don't show a linear difference between k=30 and k=60. At best there might be a 4% difference between k=3 and k=30, and k=30/k=60 look identical.
I think I was prompted to write that sentence by looking at the yellow "trunk-MDMF" line in the attachment:CHKMDMF-100MB-vs-k.png graph, which *does* show a linear slowdown with increasing k (with a lower multiplier than the new-immutable-downloader). I don't know how to reconcile the two. So something is funny, and I need to review the data, and possible run new tests.
21-May-2012: I think the timing6.out data was wrong. I'm re-running the data-gathering now, and a quick scan shows the speed dropping with increased 'k' as expected from the timing8.out data.
Attachments (12)
- CHK-1MB-k3-partial.png (60.3 KB) - added by warner at 2011-09-23T06:18:04Z.
- CHK-1MB-partial.png (97.7 KB) - added by warner at 2011-09-23T06:18:26Z.
- CHK-1MB-vs-k.png (85.8 KB) - added by warner at 2011-09-23T06:18:38Z.
- CHK-1MB-vs-segsize.png (60.7 KB) - added by warner at 2011-09-23T06:18:46Z.
- CHK-100MB-partial.png (84.9 KB) - added by warner at 2011-09-23T06:18:55Z.
- CHK-100MB-vs-k.png (75.3 KB) - added by warner at 2011-09-23T06:19:03Z.
- CHK-100MB-vs-segsize.png (54.4 KB) - added by warner at 2011-09-23T06:19:11Z.
- MDMF-1MB-partial.png (117.1 KB) - added by warner at 2011-09-23T06:19:19Z.
- MDMF-100MB-partial.png (75.6 KB) - added by warner at 2011-09-23T06:19:26Z.
- CHK-100MB-vs-segsize.2.png (54.4 KB) - added by warner at 2011-09-23T06:19:33Z.
-
atlasperf.git.tar.gz
(1.7 MB) -
added by warner at 2011-09-23T06:24:23Z.
benchmark tools and raw data
-
CHKMDMF-100MB-vs-k.png
(87.6 KB) -
added by warner at 2011-09-27T03:07:24Z.
CHK and MDMF 100MB download time, vs k
{kind=link}
{kind=link}
{kind=link}
{kind=link}